

🔎 Wyszukiwarki indeksowały prywatne rozmowy użytkowników ChataGPT

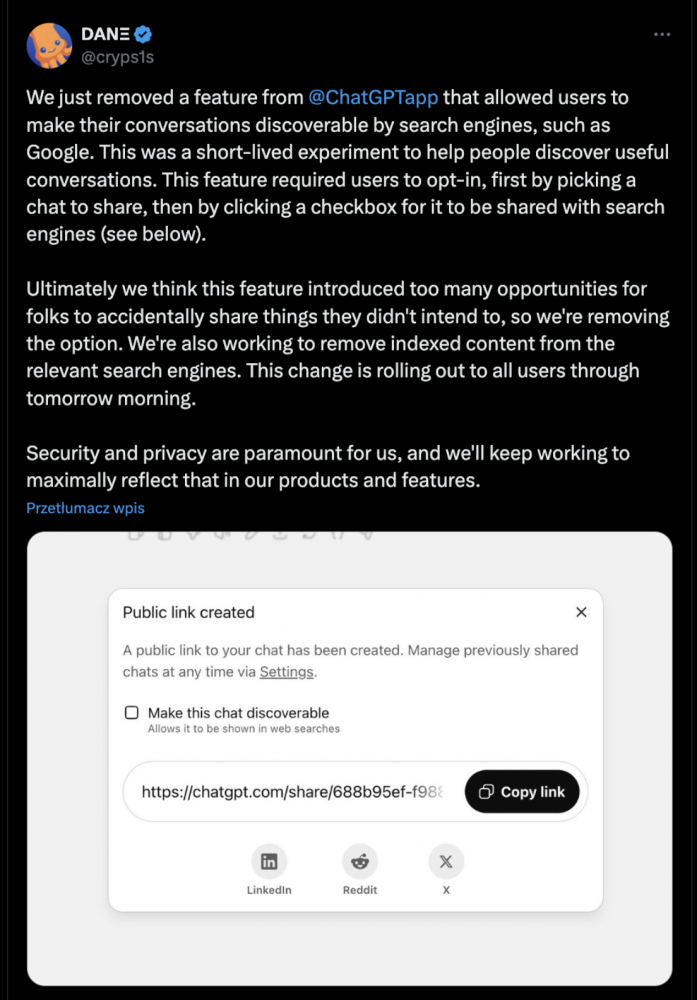
OpenAI ogłosiło, że usunął z ChataGPT funkcję, która pozwalała użytkownikom na indeksowanie ich publicznych rozmów w wyszukiwarkach. Firma określiła to jako krótkotrwały „eksperyment”, z którego wycofał się po zauważeniu, że zdarzały się przypadki niezamierzonego udostępniania, czasem bardzo prywatnej, korespondencji. OpenAI poinformował również, że pracuje nad usunięciem rozmów, które do tej pory zostały zaindeksowane przez wyszukiwarki. Mogłoby się wydawać, że wszystko jest w porządku i należy pochwalić refleksję oraz szybkie działanie OpenAI, prawda? Niestety nie. Sprawa jest nieco bardziej skomplikowana.
Źródło: https://x.com/cryps1s/status/1951041845938499669
Do niedawna, filtrując wyniki w wyszukiwarkach, wpisując site:chatgpt[.]com/share, można było zobaczyć rozmowy innych osób.
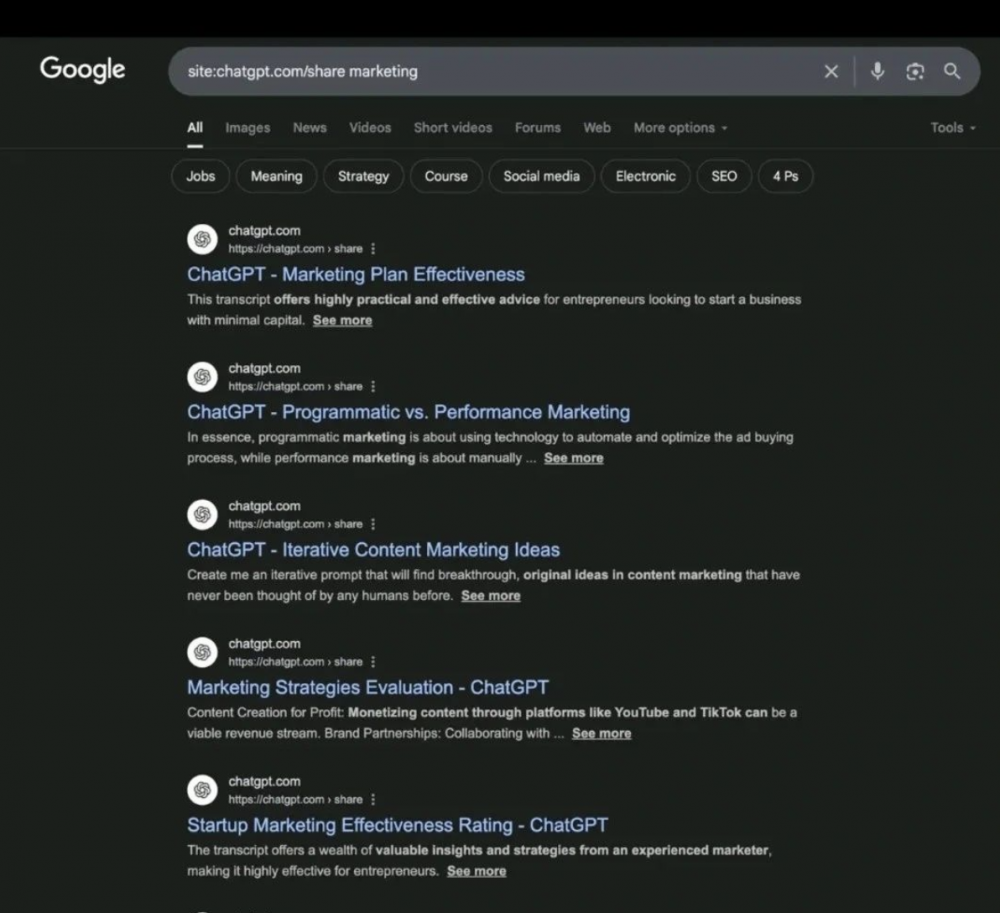
Nie było to domyślne ustawienie. Działo się tak tylko, gdy użytkownik celowo kliknął przycisk „udostępnij” w swoim czacie, a następnie „utwórz link”. Opcja zawierała również informację, że imię, opcje personalizacji asystenta (nie mylić z promptem) i wszelkie wiadomości dodane po udostępnieniu pozostają prywatne. Po kliknięciu w celu utworzenia linku, użytkownik mógł przełączyć opcję, czy chce, aby link był możliwy do odnalezienia. Czy taka informacja była wystarczająca, aby użytkownik zdawał sobie sprawę ze wszystkich konsekwencji tego działania?
Można mieć co do tego wątpliwości. TechCrunch dotarł na przykład do konwersacji, w której jeden z użytkowników prosił ChatGPT o dostosowanie swojego CV pod konkretną ofertę pracy. Dane z rozmowy pozwoliły na odnalezienie tej osoby na LinkedIn i ustalenie, że raczej nie dostała tej pracy. Użytkownik mógł nie przewidzieć, że inne wyszukiwarki zaindeksują udostępnione linki do ChataGPT, co mogło potencjalnie ujawnić dane osobowe, tak jak w tym przypadku.
„Testowaliśmy sposoby, które ułatwiają dzielenie się pomocnymi rozmowami, jednocześnie zachowując kontrolę po stronie użytkownika, i niedawno zakończyliśmy eksperyment polegający na tym, że rozmowy mogły pojawić się w wynikach wyszukiwania, jeśli użytkownik wyraźnie wyraził na to zgodę podczas udostępniania” – czytamy w wypowiedzi rzecznika OpenAI dla TechCrunch.
Rozpatrując problem od strony wyszukiwarki, warto podkreślić, że taka sama sytuacja ma miejsce, jeśli udostępni się plik z Google Drive z ustawieniem „Każdy użytkownik internetu mający ten link może wyświetlać treści”. Google może zaindeksować go w wyszukiwarce.
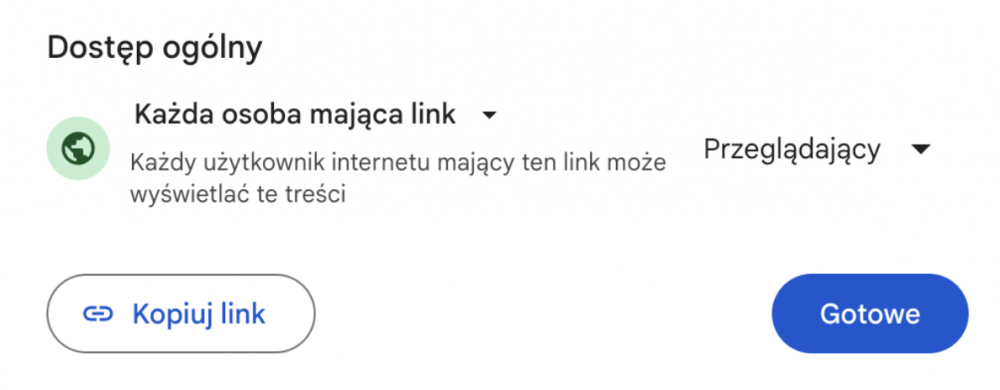
Źródło: Google Drive
Opinie użytkowników są jak zwykle podzielone. Jedni uważają, że „eksperyment” OpenAI był od początku skazany na porażkę, a testowanie nowych funkcji, które potencjalnie naruszają prywatność, niewłaściwe. Inni z kolei ubolewają nad usunięciem indeksowania treści, które pomagało im dzielić się wartościową wiedzą z innymi.
Jak wspomniano na początku, to niestety nie koniec tej historii. Niedługo po ogłoszeniu wycofania funkcji z ChataGPT w sieci pojawił się artykuł Digital Digging, który opisuje śledztwo i ujawnienie 110 000 rozmów zachowanych przez Wayback Machine, czyli Archive.org. Czyżby OpenAI zapomniał o podstawowej zasadzie Internetu, z którego „nic tak naprawdę nie znika”?
Jak donoszą badacze, w jednej z rozmów, włoskojęzyczny prawnik międzynarodowej korporacji energetycznej ujawnił strategię wysiedlenia rdzennych społeczności Amazonii. Użytkownik przedstawił się: „Jestem prawnikiem grupy międzynarodowej działającej w sektorze energetycznym, która zamierza wysiedlić małą rdzenną społeczność amazońską z ich terytoriów, by wybudować tam tamę i elektrownię wodną.”
Rozmowa miała ujawniać plany budowy elektrowni wodnej o mocy 15 000 MW, a prawnik pytał wprost: „Jak możemy wynegocjować najniższą możliwą cenę z tymi rdzennymi ludźmi?” Przyznał, że rdzenni mieszkańcy „nie znają wartości pieniężnej ziemi i nie mają pojęcia, jak działa rynek” — co w praktyce oznaczało chęć wykorzystania tej niewiedzy dla zysku korporacji.
Według Digital Digging, OpenAI, próbując posprzątać, nie wziął pod uwagę, że oprócz oryginalnych linków zostają jeszcze te zarchiwizowane i każdy, kto je zna (lub wie, jak szukać), dzięki archive.org i innym archiwizatorom, nadal ma do nich dostęp.
Źródło: sekurak.pl